We are thrilled to introduce Seed-Coder, a powerful, transparent, and parameter-efficient family of open-source code models at the 8B scale, featuring base, instruct, and reasoning variants. Seed-Coder contributes to promote the evolution of open code models through the following highlights.
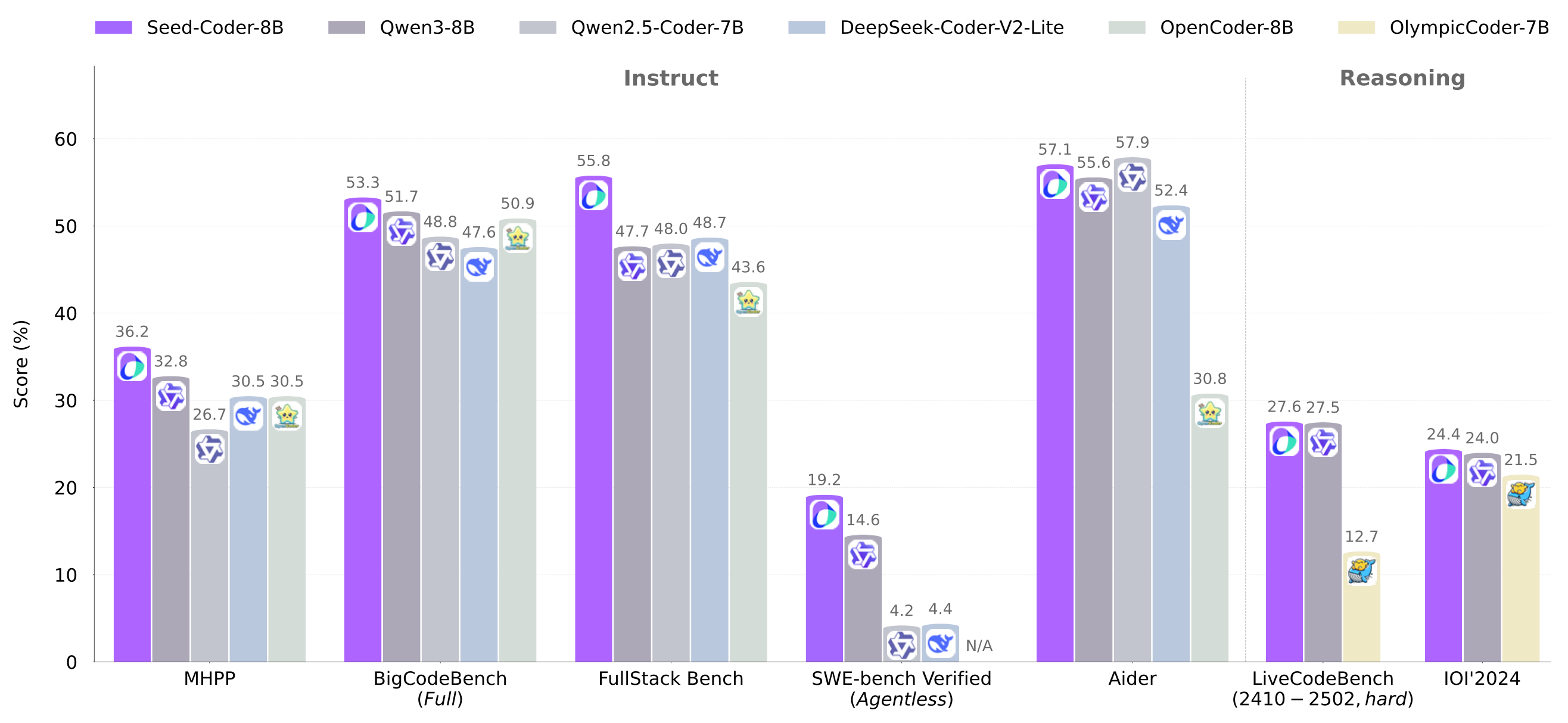
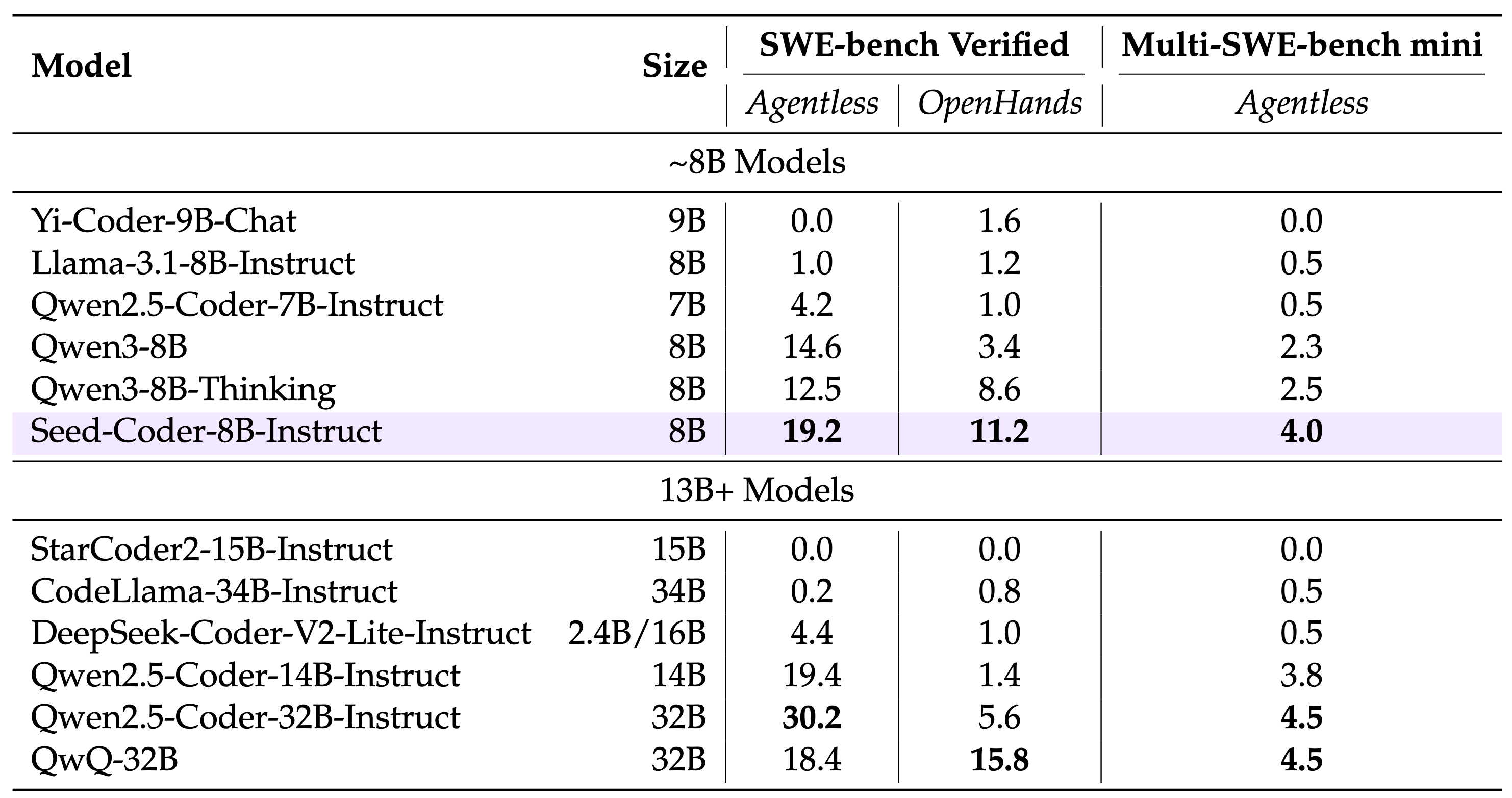
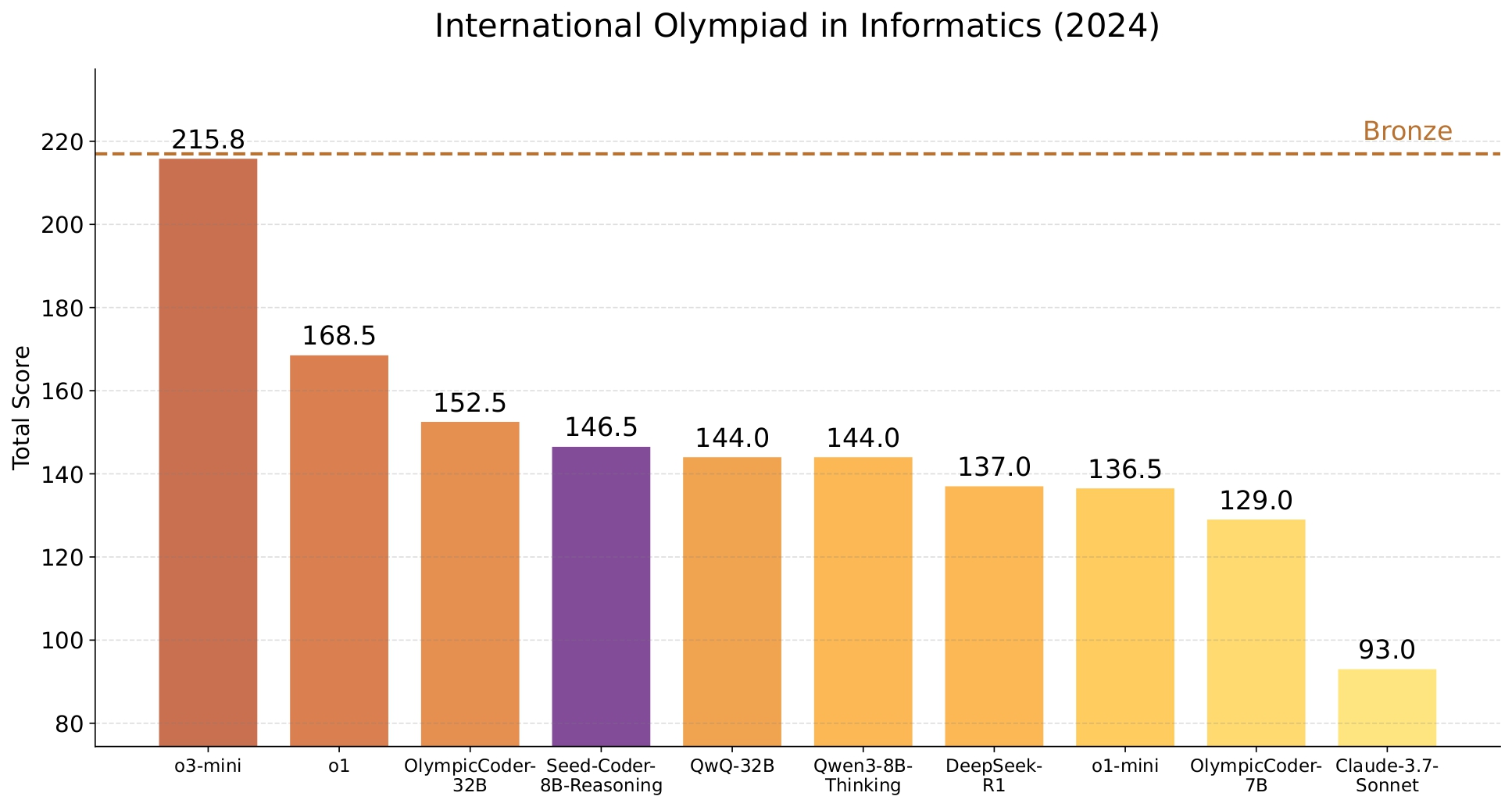
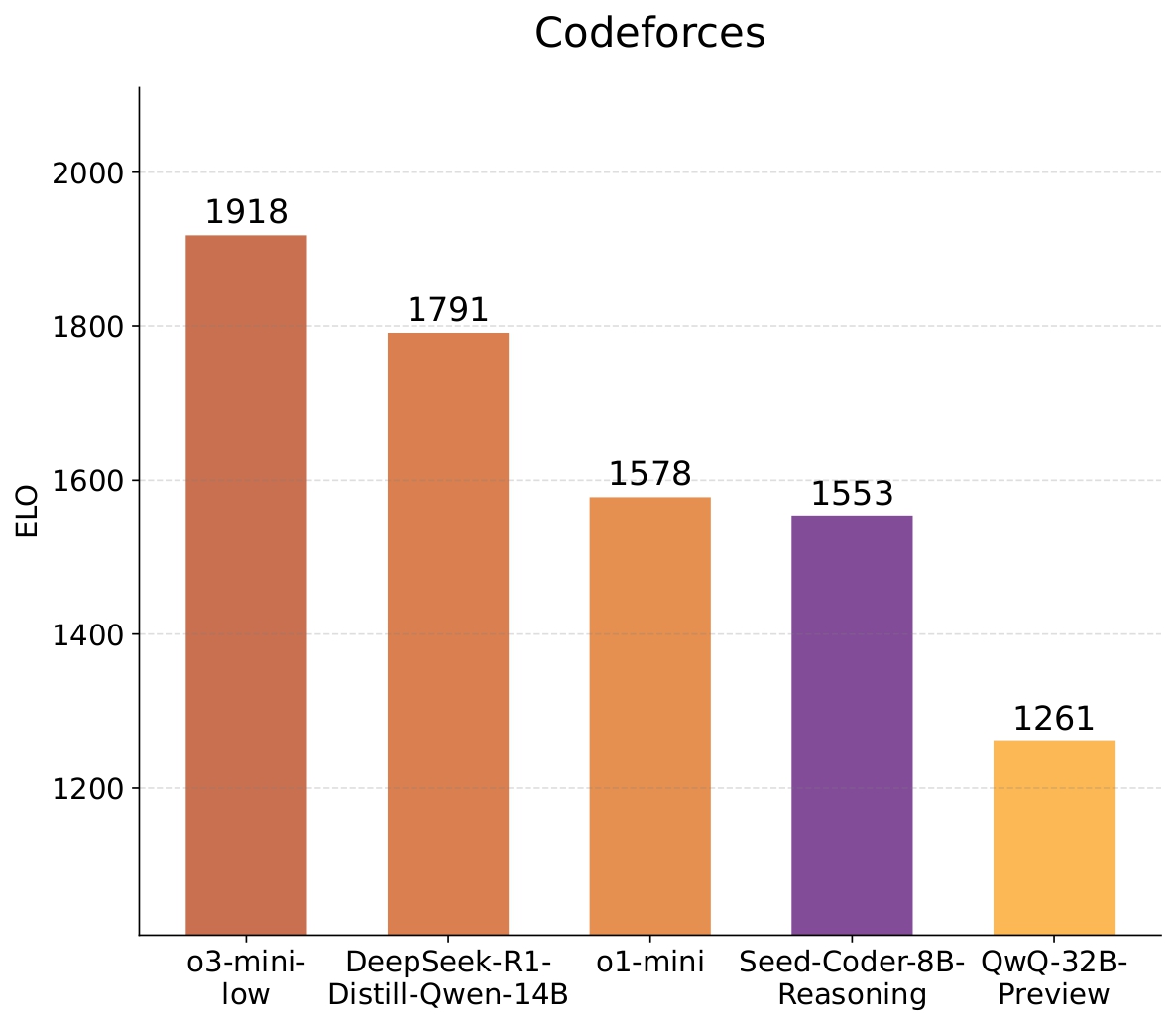
Benchmark performance of instruct and reasoning variants of Seed-Coder-8B.
Introduction
1
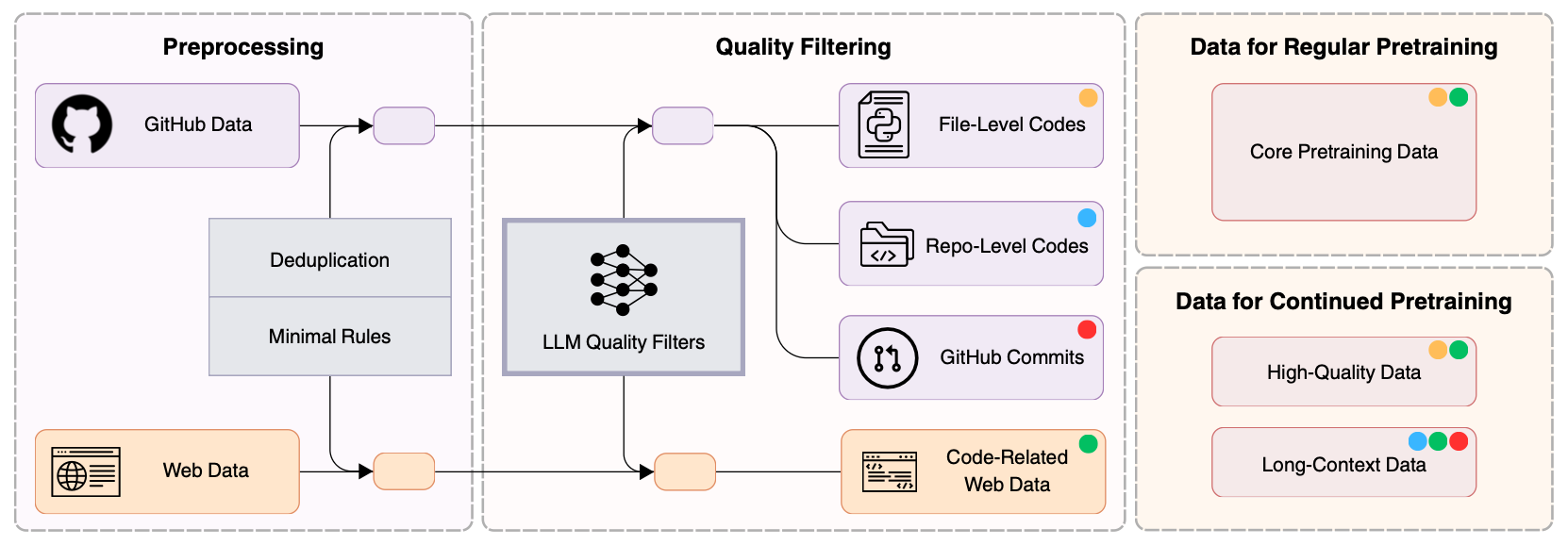
Model-centric: Seed-Coder predominantly leverages LLMs instead of hand-crafted rules for code data filtering, minimizing manual effort in pretraining data construction.
2
Transparent: We openly share detailed insights into our model-centric data pipeline, including methods for curating GitHub data, commits data, and code-related web data.
3
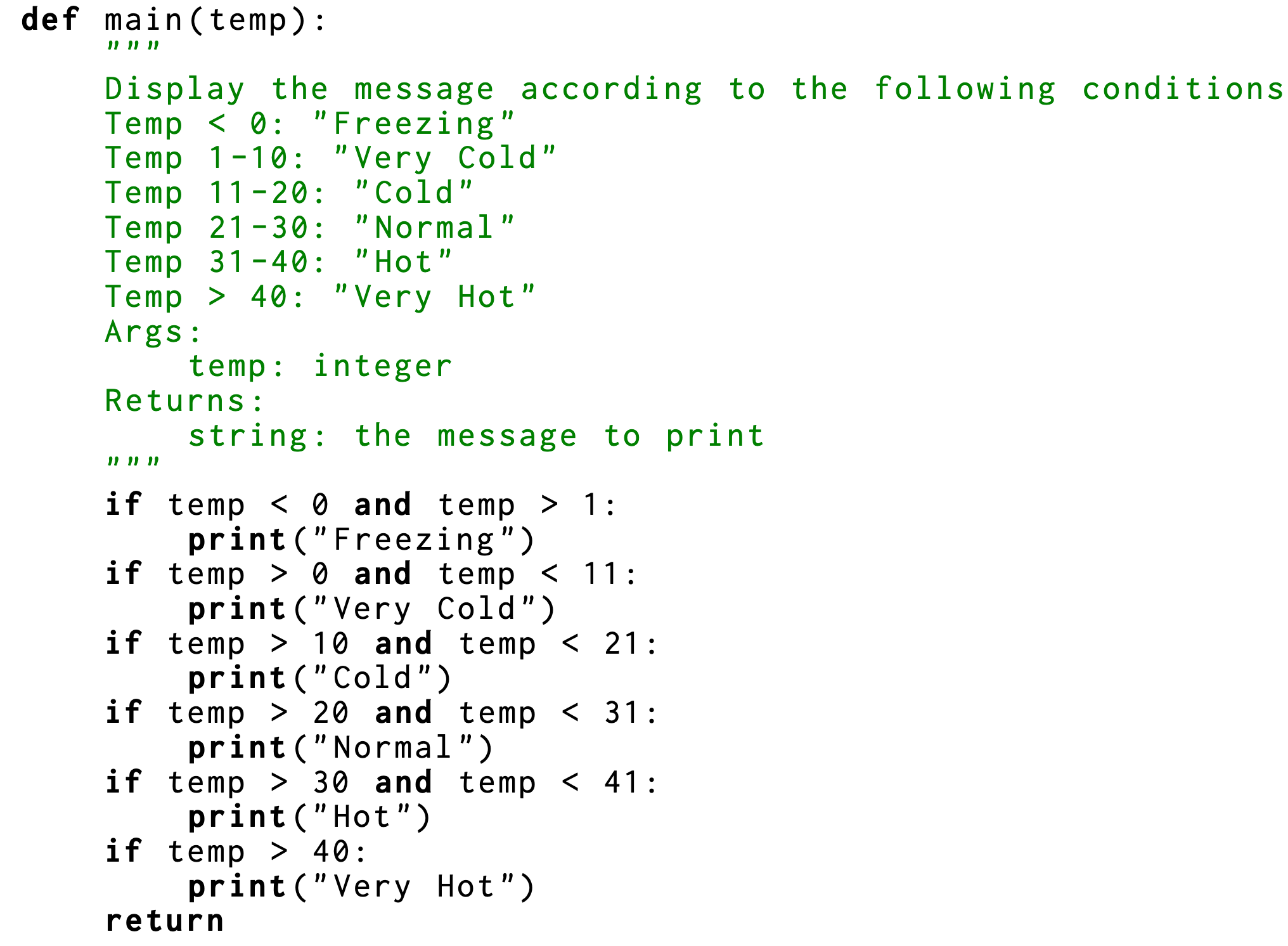
Powerful: Seed-Coder achieves state-of-the-art performance among open-source models of comparable size across a diverse range of coding tasks.
Seed-Coder demonstrates that, with minimal human effort, LLMs can effectively curate code training data by themselves to drastically enhance coding capabilities. 🚨 The Bitter Lesson holds true — this time in code LLMs!
Seed-Coder represents our initial step towards contributing to the open-source LLM ecosystem. We look forward to seeing Seed-Coder drive advances in code intelligence and empower broader applications in the open-source LLM community!